神级美女系统txt-Transformers20让你三行代码调用语言模型,兼容TF20和PyTorc
2023-09-21 富美财经 浏览量:次
机器之心报道
机器之心编辑部
能够灵活地调用各种语言模型,一直是 NLP 研究者的期待。近日 HuggingFace 公司开源了最新的 Transformer2.0 模型库,用户可非常方便地调用现在非常流行的 8 种语言模型进行微调和应用,且同时兼容 TensorFlow2.0 和 PyTorch 两大框架,非常方便快捷。
最近,专注于自然语言处理(NLP)的初创公司 HuggingFace 对其非常受欢迎的 Transformers 库进行了重大更新,从而为 PyTorch 和 Tensorflow 2.0 两大深度学习框架提供了前所未有的兼容性。
更新后的 Transformers 2.0 汲取了 PyTorch 的易用性和 Tensorflow 的工业级生态系统。借助于更新后的 Transformers 库,科学家和实践者可以更方便地在开发同一语言模型的训练、评估和制作阶段选择不同的框架。
那么更新后的 Transformers 2.0 具有哪些显著的特征呢?对 NLP 研究者和实践者又会带来哪些方面的改善呢?机器之心进行了整理。
项目地址:https://github.com/huggingface/transformers
Transformers 2.0 新特性
- 像 pytorch-transformers 一样使用方便;
- 像 Keras 一样功能强大和简洁;
- 在 NLU 和 NLG 任务上实现高性能;
- 对教育者和实践者的使用门槛低。
为所有人提供 SOTA 自然语言处理
- 深度学习研究者;
- 亲身实践者;
- AI/ML/NLP 教师和教育者。
更低的计算开销和更少的碳排放量
- 研究者可以共享训练过的模型,而不用总是重新训练;
- 实践者可以减少计算时间和制作成本;
- 提供有 8 个架构和 30 多个预训练模型,一些模型支持 100 多种语言;
为模型使用期限内的每个阶段选择正确的框架
- 3 行代码训练 SOTA 模型;
- 实现 TensorFlow 2.0 和 PyTorch 模型的深度互操作;
- 在 TensorFlow 2.0 和 PyTorch 框架之间随意移动模型;
- 为模型的训练、评估和制作选择正确的框架。
现已支持的模型
官方提供了一个支持的模型列表,包括各种著名的预训练语言模型和变体,甚至还有官方实现的一个蒸馏后的 Bert 模型:
1. BERT (https://github.com/google-research/bert) 2. GPT (https://github.com/openai/finetune-transformer-lm) 3. GPT-2 (https://blog.openai.com/better-language-models/) 4. Transformer-XL (https://github.com/kimiyoung/transformer-xl) 5. XLNet (https://github.com/zihangdai/xlnet/)6. XLM (https://github.com/facebookresearch/XLM/) 7. RoBERTa (https://github.com/pytorch/fairseq/tree/master/examples/roberta) 8. DistilBERT (https://github.com/huggingface/transformers/tree/master/examples/distillation)
快速上手
怎样使用 Transformers 工具包呢?官方提供了很多代码示例,以下为查看 Transformer 内部模型的代码:
import torchfrom transformers import *#Transformers has a unified API#for 8 transformer architectures and 30 pretrained weights.#Model | Tokenizer | Pretrained weights shortcutMODELS = [(BertModel, BertTokenizer, 'bert-base-uncased'), (OpenAIGPTModel, OpenAIGPTTokenizer, 'openai-gpt'), (GPT2Model, GPT2Tokenizer, 'gpt2'), (TransfoXLModel, TransfoXLTokenizer, 'transfo-xl-wt103'), (XLNetModel, XLNetTokenizer, 'xlnet-base-cased'), (XLMModel, XLMTokenizer, 'xlm-mlm-enfr-1024'), (DistilBertModel, DistilBertTokenizer, 'distilbert-base-uncased'), (RobertaModel, RobertaTokenizer, 'roberta-base')]#To use TensorFlow 2.0 versions of the models, simply prefix the class names with 'TF', e.g. TFRobertaModel is the TF 2.0 counterpart of the PyTorch model RobertaModel#Let's encode some text in a sequence of hidden-states using each model:for model_class, tokenizer_class, pretrained_weights in MODELS: # Load pretrained model/tokenizer tokenizer = tokenizer_class.from_pretrained(pretrained_weights) model = model_class.from_pretrained(pretrained_weights) # Encode text input_ids = torch.tensor([tokenizer.encode("Here is some text to encode", add_special_tokens=True)]) # Add special tokens takes care of adding [CLS], [SEP], <s>... tokens in the right way for each model. with torch.no_grad(): last_hidden_states = model(input_ids)[0] # Models outputs are now tuples#Each architecture is provided with several class for fine-tuning on down-stream tasks, e.g.BERT_MODEL_CLASSES = [BertModel, BertForPreTraining, BertForMaskedLM, BertForNextSentencePrediction, BertForSequenceClassification, BertForMultipleChoice, BertForTokenClassification, BertForQuestionAnswering]#All the classes for an architecture can be initiated from pretrained weights for this architecture#Note that additional weights added for fine-tuning are only initialized#and need to be trained on the down-stream tasktokenizer = BertTokenizer.from_pretrained('bert-base-uncased')for model_class in BERT_MODEL_CLASSES: # Load pretrained model/tokenizer model = model_class.from_pretrained('bert-base-uncased')#Models can return full list of hidden-states & attentions weights at each layermodel = model_class.from_pretrained(pretrained_weights, output_hidden_states=True, output_attentions=True)input_ids = torch.tensor([tokenizer.encode("Let's see all hidden-states and attentions on this text")])all_hidden_states, all_attentions = model(input_ids)[-2:]#Models are compatible with Torchscriptmodel = model_class.from_pretrained(pretrained_weights, torchscript=True)traced_model = torch.jit.trace(model, (input_ids,))#Simple serialization for models and tokenizersmodel.save_pretrained('./directory/to/save/') # savemodel = model_class.from_pretrained('./directory/to/save/') # re-loadtokenizer.save_pretrained('./directory/to/save/') # savetokenizer = tokenizer_class.from_pretrained('./directory/to/save/') # re-load#SOTA examples for GLUE, SQUAD, text generation...Transformers 同时支持 PyTorch 和 TensorFlow2.0,用户可以将这些工具放在一起使用。如下为使用 TensorFlow2.0 和 Transformer 的代码:
import tensorflow as tfimport tensorflow_datasetsfrom transformers import *#Load dataset, tokenizer, model from pretrained model/vocabularytokenizer = BertTokenizer.from_pretrained('bert-base-cased')model = TFBertForSequenceClassification.from_pretrained('bert-base-cased')data = tensorflow_datasets.load('glue/mrpc')#Prepare dataset for GLUE as a tf.data.Dataset instancetrain_dataset = glue_convert_examples_to_features(data['train'], tokenizer, max_length=128, task='mrpc')valid_dataset = glue_convert_examples_to_features(data['validation'], tokenizer, max_length=128, task='mrpc')train_dataset = train_dataset.shuffle(100).batch(32).repeat(2)valid_dataset = valid_dataset.batch(64)#Prepare training: Compile tf.keras model with optimizer, loss and learning rate schedule optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')model.compile(optimizer=optimizer, loss=loss, metrics=[metric])#Train and evaluate using tf.keras.Model.fit()history = model.fit(train_dataset, epochs=2, steps_per_epoch=115, validation_data=valid_dataset, validation_steps=7)#Load the TensorFlow model in PyTorch for inspectionmodel.save_pretrained('./save/')pytorch_model = BertForSequenceClassification.from_pretrained('./save/', from_tf=True)#Quickly test a few predictions - MRPC is a paraphrasing task, let's see if our model learned the tasksentence_0 = "This research was consistent with his findings.“sentence_1 = "His findings were compatible with this research.“sentence_2 = "His findings were not compatible with this research.“inputs_1 = tokenizer.encode_plus(sentence_0, sentence_1, add_special_tokens=True, return_tensors='pt')inputs_2 = tokenizer.encode_plus(sentence_0, sentence_2, add_special_tokens=True, return_tensors='pt')pred_1 = pytorch_model(*inputs_1)[0].argmax().item()pred_2 = pytorch_model(*inputs_2)[0].argmax().item()print("sentence_1 is", "a paraphrase" if pred_1 else "not a paraphrase", "of sentence_0")print("sentence_2 is", "a paraphrase" if pred_2 else "not a paraphrase", "of sentence_0")使用 py 文件脚本进行模型微调
当然,有时候你可能需要使用特定数据集对模型进行微调,Transformer2.0 项目提供了很多可以直接执行的 Python 文件。例如:
- run_glue.py:在九种不同 GLUE 任务上微调 BERT、XLNet 和 XLM 的示例(序列分类);
- run_squad.py:在问答数据集 SQuAD 2.0 上微调 BERT、XLNet 和 XLM 的示例(token 级分类);
- run_generation.py:使用 GPT、GPT-2、Transformer-XL 和 XLNet 进行条件语言生成;
- 其他可用于模型的示例代码。
GLUE 任务上进行模型微调
如下为在 GLUE 任务进行微调,使模型可以用于序列分类的示例代码,使用的文件是 run_glue.py。
首先下载 GLUE 数据集,并安装额外依赖:
pip install -r ./examples/requirements.txt
然后可进行微调:
export GLUE_DIR=/path/to/glueexport TASK_NAME=MRPCpython ./examples/run_glue.py --model_type bert --model_name_or_path bert-base-uncased --task_name $TASK_NAME --do_train --do_eval --do_lower_case --data_dir $GLUE_DIR/$TASK_NAME --max_seq_length 128 --per_gpu_eval_batch_size=8 --per_gpu_train_batch_size=8 --learning_rate 2e-5 --num_train_epochs 3.0 --output_dir /tmp/$TASK_NAME/
在命令行运行时,可以选择特定的模型和相关的训练参数。
使用 SQuAD 数据集微调模型
另外,你还可以试试用 run_squad.py 文件在 SQuAD 数据集上进行微调。代码如下:
python -m torch.distributed.launch --nproc_per_node=8 ./examples/run_squad.py --model_type bert --model_name_or_path bert-large-uncased-whole-word-masking --do_train --do_eval --do_lower_case --train_file $SQUAD_DIR/train-v1.1.json --predict_file $SQUAD_DIR/dev-v1.1.json --learning_rate 3e-5 --num_train_epochs 2 --max_seq_length 384 --doc_stride 128 --output_dir ../models/wwm_uncased_finetuned_squad/ --per_gpu_eval_batch_size=3 --per_gpu_train_batch_size=3
这一代码可微调 BERT 全词 Mask 模型,在 8 个 V100GPU 上微调,使模型的 F1 分数在 SQuAD 数据集上超过 93。
用模型进行文本生成
还可以使用 run_generation.py 让预训练语言模型进行文本生成,代码如下:
python ./examples/run_generation.py --model_type=gpt2 --length=20 --model_name_or_path=gpt2
安装方法
如此方便的工具怎样安装呢?用户只要保证环境在 Python3.5 以上,PyTorch 版本在 1.0.0 以上或 TensorFlow 版本为 2.0.0-rc1。
然后使用 pip 安装即可。
pip install transformers
移动端部署很快就到
HuggingFace 在 GitHub 上表示,他们有意将这些模型放到移动设备上,并提供了一个 repo 的代码,将 GPT-2 模型转换为 CoreML 模型放在移动端。
未来,他们会进一步推进开发工作,用户可以无缝地将大模型转换成 CoreML 模型,无需使用额外的程序脚本。
repo 地址:https://github.com/huggingface/swift-coreml-transformers

-
-
优秀!祝贺空军首批“双学籍”女飞
近日由空军和清华大学北京大学联合培养的首批“双学籍”女飞行学员顺利完...

- 国内财经 2024-05-09
-
优秀!祝贺空军首批“双学籍”女飞
-
-
负面情绪正持续发酵 多国计划加强对ChatGPT监管
图为2023年11月7日,在第五届进博会技术装备展区的人工智能专区,体验者借...

- 国内财经 2024-05-09
-
负面情绪正持续发酵 多国计划加强对ChatGPT监管
-
-
强降雨引发洪水 江西安远紧急避险200余户村民
4月5日凌晨,江西赣州安远县遭遇突发恶劣的强降水、雷雨天气,引发洪水,...

- 国内财经 2024-05-09
-
强降雨引发洪水 江西安远紧急避险200余户村民
-
-
第20届中国-东盟博览会新加坡巡展开幕
第20届中国-东盟博览会新加坡巡展暨国际陆海贸易新通道、“桂品出海”开幕...

- 国内财经 2024-05-09
-
第20届中国-东盟博览会新加坡巡展开幕
-
-
江苏发布海域海浪Ⅳ级蓝色警报
江苏省海洋环境监测预报中心根据《江苏省海洋灾害应急预案》发布江苏海域...
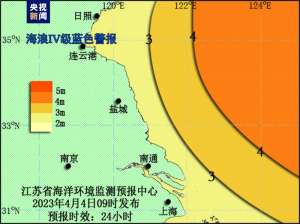
- 国内财经 2024-05-09
-
江苏发布海域海浪Ⅳ级蓝色警报
-
-
印度一百年老树因暴雨倒塌 已致7死30伤
据《印度论坛报》4月10日报道,受到暴雨影响,当地时间4月9日晚,印度马哈...
- 国内财经 2024-05-09
-
印度一百年老树因暴雨倒塌 已致7死30伤