索引表(索引是怎么支撑千万级表的快速查找)
2023-04-26 富美财经 浏览量:次
8分钟阅读.
一、背景
在企业开发中建表的时候一般都会创建索引,那为什么要创建索引呢?这个大家都知道:为了提高查询的性能。那为什么索引能够实现快速查找 ?而且能够支撑千万级表的快速查找?还有在实际开发中有一个不成文规则,当mysql的单表数据量达到千万级时[约是2KW],必须要进行分库分表的操作。本文来展开介绍。
二、什么是索引
首先来了解下索引是什么?索引的本质:是排好序的数据结构。
三、为什么索引能提高查询性能
1、索引能够提高查询性能
为什么索引能够提高查询性能呢?我们先从以下这张图说起。

图的左侧是表索引前的表的数据结构,右侧是创建索引后的索引的数据结构。
我们来看下如果要执行查询sql:select * from 表 where col2=89,背后的执行逻辑是?
没建索引之前数据是无序的,也没有依赖什么数据结构。查找的时候要进行全表扫描遍历,查询的时间复杂度为o(n)。
建索引之后,数据变成了基于平衡二叉树数据结构建立的有序数据,索引的Key为col2,Value为该数据的指针地址。在查询的时候,从34根节点开始查,遍历二次就可以找到89这条数据,其查询时间复杂度为o(log2n),近似于折半查找。
结论:建索引后肯定比建索引前的性能要高。
2、索引能够支持千万级表快速查找
那么数据库表的索引就是基于上图中平衡二叉树的数据结构实现的吗?
我们来思考一个问题:如果表中有65535条数据,即使基于平衡二叉树建立索引后,由于其时间复杂度为o(log2n) ,那它的查询次数为:16次。一次Sql查询需要16次的磁盘IO操作这个性能显然不高。
小伙伴可能会说我们只通过一次性磁盘IO操作把数据全部加载到内存里,余下的查询操作在内存中进行,这样就能够提高查询性能。这种想法是对的,但试想如果数据量增大,数据达到千万级量的时,是不可能一次性将所有数据都加载到内存中。所以数据库索引的数据结构不是基于平衡二叉树建立的。
另外平衡二叉树有个特点是:最长子节点和最短子节点的深度差不能超过1层,所以在插入后,会进行平衡调整。这样决定了其插入数据的性能较低。
以上可以说明数据库表的索引的数据结构不是基于平衡二叉树。
小贴士:不理解平衡二叉树,可以补下数据结构的知识。有个数据结构可视化的网站不错https://www.cs.usfca.edu/~galles/visualization/Algorithms.html 有各种数据结构,可以复习下。
那数据库表的索引是基于什么样的数据结构呢?大家都不难知道索引的数据结构是B+tree。
索引的优化思路就是减少磁盘IO操作,将计算尽可能的放到内存中,从而实现快速查找。基于减少磁盘IO的思路,如何来对平衡二叉树的数据结构进行改造、升级呢?那就是把即把平衡二叉树变成多叉平衡树,树的深度设置为一层,这样IO操作只需一次,但问题是无法将所有数据加载到内存中(数据量大时、内存空间不足)。继续思考如何进行改造?那么我们来看B+tree的数据存储结构。

B+tree的特点:
1、非叶子节点不存储data,只存储索引;
2、顺序访问指针,提高区间访问性能。
索引的思路减少磁盘IO操作和将计算尽可能放到内存中。Mysql采取了一个折中的方案:在满足B+tree的特点的基础上,将树的节点存储容量设置为定量的数据 – 可以将数据加载到内存中来计算;将树的深度h设置为N(N<=5) – 可减少IO操作。
Mysql定义了pageSize的大小约为16KB(节点存储大小定量),树的深度h=3(前两层存放索引Key+指针,最后一层存放索引key+data),来支撑千万级数据的快速查找。
pageSize对应的是B+tree每一个节点的空间大小。
我们知道mysql中定义了:bigint 占用8byte(索引Key的大小,一般用bigint类型的字段进行索引),磁盘文件地址指针占用 6byte(文件地址的大小)
那么:pageSize/(索引Key+文件地址指针)=树前两层单个节点存储的索引元素量即:16KB/(8+6)byte=1170个元素。
假如我们假定一条row数据的大小为1KB (一般表行数据大小也就1KB)。
pageSize/rowSize=树第三层单个节点存储的索引元素量即:16KB/1KB = 16个元素。
那么总的索引元素量即数据量=1170 * 1170 * 16 = 2KW。(树的深度h=3,第一、二层非叶子节点:元素个数为 1170*1170,第三层单个叶子节点存储的元素个数为16,所以总数量为:1170*1170*16 = 2KW)
B+tree 特点:顺序访问指针,提高区间访问性能。即获取区间Key的速度会很快。
其实以上只是简单说明B+tree的数据结构,Mysql中的索引结构还比以上复杂,但通过以上可以理解索引为什么能够支撑千万级表的快速查找,为什么数据量约是2KW。
数据库索引数据结构除了B+tree数据结构,还有Hash结构。基于Hash结构,获取单Key的速度很快,但获取区间Key的速度会很慢。实际开发中很少用到。
四、小结
1、索引的本质是排好序的数据结构,索引的优化思路是减少磁盘IO操作和将计算尽可能放到内存中,从而支撑快速查找。
2、通过B+tree数据结构的分析,得出B+tree的特点:非叶子节点不存储data,只存储索引;顺序访问指针,提高区间访问性能。更重要的是Mysql基于B+tree的特点进行了折中设计,这种设计使其索引支撑千万级表的快速查找,并进行了估算来证实为何是千万级。
3、索引的数据结构基于B+tree、Hash数据结构。(在实际开发中很少用Hash数据结构,原因获取区间Key的速度慢)。
如果此文能帮小伙伴答疑解惑,请关注「架构那些事儿」!
你的关注就是我的动力!

-
-
优秀!祝贺空军首批“双学籍”女飞
近日由空军和清华大学北京大学联合培养的首批“双学籍”女飞行学员顺利完...

- 国内财经 2024-05-09
-
优秀!祝贺空军首批“双学籍”女飞
-
-
负面情绪正持续发酵 多国计划加强对ChatGPT监管
图为2023年11月7日,在第五届进博会技术装备展区的人工智能专区,体验者借...

- 国内财经 2024-05-09
-
负面情绪正持续发酵 多国计划加强对ChatGPT监管
-
-
强降雨引发洪水 江西安远紧急避险200余户村民
4月5日凌晨,江西赣州安远县遭遇突发恶劣的强降水、雷雨天气,引发洪水,...

- 国内财经 2024-05-09
-
强降雨引发洪水 江西安远紧急避险200余户村民
-
-
第20届中国-东盟博览会新加坡巡展开幕
第20届中国-东盟博览会新加坡巡展暨国际陆海贸易新通道、“桂品出海”开幕...

- 国内财经 2024-05-09
-
第20届中国-东盟博览会新加坡巡展开幕
-
-
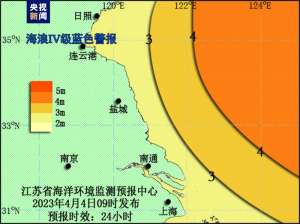
江苏发布海域海浪Ⅳ级蓝色警报
江苏省海洋环境监测预报中心根据《江苏省海洋灾害应急预案》发布江苏海域...
- 国内财经 2024-05-09
-
江苏发布海域海浪Ⅳ级蓝色警报
-
-
印度一百年老树因暴雨倒塌 已致7死30伤
据《印度论坛报》4月10日报道,受到暴雨影响,当地时间4月9日晚,印度马哈...
- 国内财经 2024-05-09
-
印度一百年老树因暴雨倒塌 已致7死30伤